Web Mining: Was ist das eigentlich?
Zurück zum BlogEine Säule von Big Data Analytics ist die Verfügbarkeit von analysierbaren Daten. Stammen diese nicht aus unternehmensinternen Quellen, müssen sie aus anderen Quellen beschafft werden. Im Internet, oder spezieller dem World Wide Web, stehen frei zugängliche Informationen im Überfluss zur Verfügung. Um diese nutzbar zu machen, benötigt man Web Mining.
Definition:
Neben urheberrechtlich geschützten Quellen, welche nur zu Forschungszwecken ausgewertet werden dürfen, gibt es auch eine Vielzahl an Open-Source-Quellen oder Quellen aus öffentlicher Hand, die zur kommerziellen Analyse herangezogen werden können. Viele dieser Informationen wurden jedoch nicht für die maschinelle Verarbeitung geschaffen und können somit nicht ohne vorherige Transformation zur Analyse herangezogen werden. Web Mining, genauer Web Content Mining, stellt verschiedene Verfahren bereit, um solcher Daten habhaft zu werden und sie für die weitere Analyse vorzubereiten.
Eine wichtige Fragestellung ergibt sich bei der Speicherung von personenbezogenen und personenbeziehbaren Daten, der Datenschutz. Hierbei ist sicher zu stellen, dass keine Daten gespeichert werden, welche einen Personenbezug erlauben. Sind für den spezifischen Use Case solche Daten erforderlich, so ist sicherzustellen, dass diese bereits vor der Speicherung bzw. Weiterverarbeitung anonymisiert werden. Durch die frühe Anonymisierung und den Verzicht auf die Speicherung der nicht-anonymisierten Daten bleibt der Datenschutz und damit der Schutz der persönlichen Information gewahrt. Das bekommt vor dem Hintergrund der im Mai in Kraft tretenden DSGVO bei allen Unternehmen und Behörden eine noch größere Bedeutung.
Wie liegen Informationen im Web vor?
Informationen im World Wide Web können auf vielfältige Art und Weise vorliegen. Eine einzelne Website enthält dabei viele verschiedene Arten der Informationsrepräsentanz. Die Website von Empolis beispielsweise beheimatet neben textuellen Informationen auch Bilder und Grafiken, Videos sowie PDF-Dokumente.
Mit Blick auf das gesamte World Wide Web und die großen sozialen Netzwerke, mit ihrem direkt von Endnutzern bereitgestellten Content, wird die Liste an möglichen Datentypen schier unendlich. Das stellt das Web Mining vor große Herausforderungen, da neben der Unterstützung unterschiedlicher Kommunikationsprotokolle auch für die meisten Datentypen individuelle Verfahren zur Informationsextraktion angewendet werden müssen.
Ziel aller Verfahren ist es, Informationen, die primär für die Verarbeitung und den Konsum durch Menschen vorgesehen sind, in eine Form zu überführen, die eine effektive und vollautomatisierte Analyse der gewonnenen Daten erlaubt. Hierbei erfolgt zumeist eine Umwandlung der ursprünglichen Datenrepräsentanz, da die Ansprüche eines informationsverarbeitenden Systems andere sind, als die an eine für den Menschen optimierten Ansicht.
Wie funktioniert Web Mining?
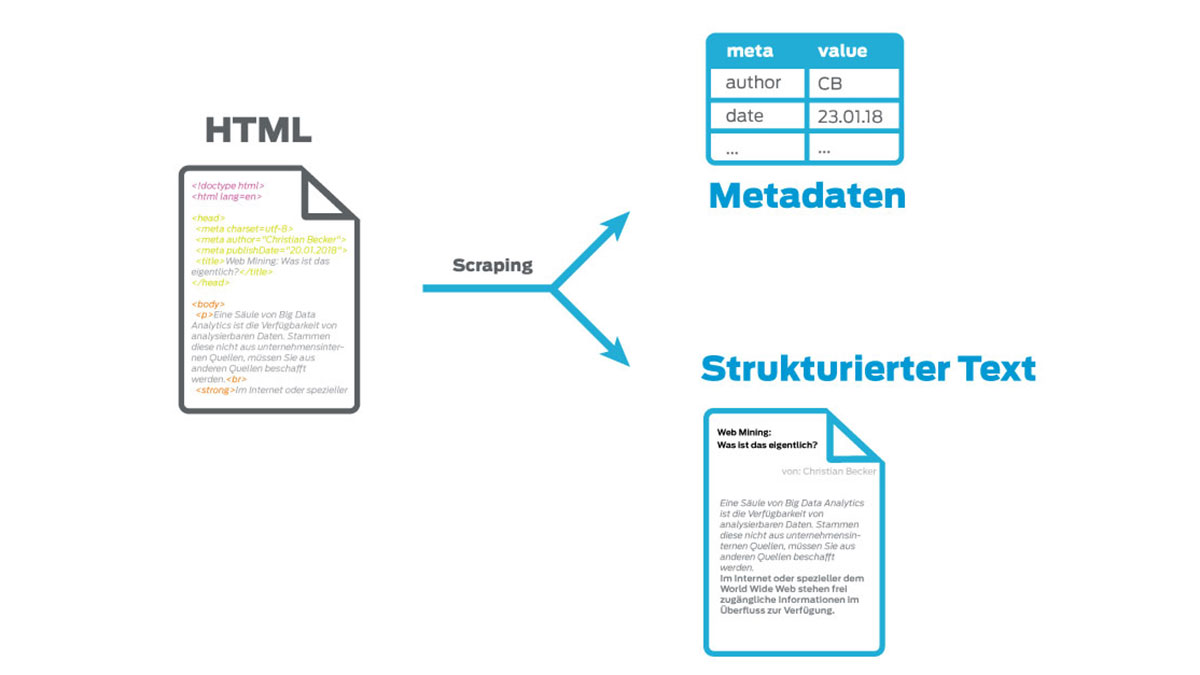
Im Folgenden betrachten wir das Beispiel einer einzelnen Seite einer Website. Ausgangspunkt ist ein HTML-Dokument, welches die technische und inhaltliche Beschreibung der Website beinhaltet. Wirft man einen Blick auf die Struktur des HTML-Dokuments, stellt man schnell fest, dass ein Großteil der hinterlegten Informationen technischer Natur sind und keine Relevanz für das Web Mining haben. Dies sind primär Stylesheets, welche die optische Erscheinung der Seite steuern und JavaScripts zur Optimierung der User Experience. Daneben sind viele Steuerinformationen enthalten, welche den Aufbau der Seite bestimmen.
Auf den ersten Blick könnte man auf solche Steuerinformationen verzichten und diese im Zuge der Informationsextraktion eliminieren. Jedoch kann die Struktur der abgelegten Informationen entscheidend für deren korrekte Interpretation sein. Einem Satz, der in kleingedruckter Schrift am Ende der Seite steht, wird der Leser einen anderen Stellenwert zuordnen als einem Satz, der prominent in fetten Buchstaben den Beginn eines Nachrichtenartikels ankündigt. Entsprechend ist bei der Reduktion der Informationen ein Use Case spezifisches Fingerspitzengefühl erforderlich.
Neben den Informationen, welche sich direkt aus dem für den Menschen geschaffenen Inhalt ableiten lassen, gibt es in HTML-Dokumenten häufig weitere sogenannte Meta-Informationen wie Titel, Zusammenfassung, Autor und viele weitere, welche explizit für die maschinelle Verarbeitung vorgesehen sind. Was sich auf den ersten Blick als ein Schatz für jeden Web Miner darstellt, wird auf den zweiten Blick schnell zum Alptraum der Abteilung, die für die Entwicklung der Web Mining Tools beauftragt ist. Nicht nur, dass es verschiedenste offene Standards für die Annotation von Meta-Informationen gibt, sie werden auch häufig falsch umgesetzt.
Eine weitere Herausforderung für das Web Mining stellt die wachsende Bandbreite an verfügbaren Frameworks zur Gestaltung von Websites dar, die die Dokumente in jeweils eigener – und nach einem regelmäßig nicht dokumentierten Schema – um weitere Attribute zur Steuerung der Anzeige erweitern. Das macht die HTML-Strukturen nicht nur komplexer, sondern erschwert auch deren Interpretation.
Das stellt auch aktuelle Extraktionsverfahren vor erhebliche Herausforderungen. Zudem führen immer mehr Websites ihren Content nicht im HTML mit, sondern laden diesen per JavaScript zum Zeitpunkt der Anzeige der Website dynamisch nach. In solchen Fällen können Informationen nur durch rechenintensive Darstellung in einem Browser oder durch speziell auf die Website optimierte Extraktionsverfahren gewonnen werden.
Erweitert man diese Sicht nun auf die komplette Website, so kommen Verlinkungen zwischen den einzelnen Seiten und über die Website hinaus hinzu. Je nach Use Case können auch diese Referenzen einen relevanten Informationsgehalt haben.
Web Mining: Die Basis für Big Data Analytics
Web Mining ist eine mächtige Basis für die Datenbeschaffung im Rahmen von Big Data Analytics. Dabei stehen wachsende technische Anforderungen, aufgrund immer stärker dynamisch aufgebauter Websites und Webservices, Seite an Seite mit der notwenigen fachlichen Expertise zur zielgerichteten Extraktion und Interpretation der benötigten Informationen.
So stellt Web Content Mining im Kontext von Big Data schon heute eine wichtige Technologie dar und wird diese Stellung in Zukunft halten oder sogar ausbauen.